Recommender Systems — Know your users better than they know themselves
A dive into the traditional methods and approaches to recommender systems, with a spotlight on Collaborative Filtering
I think we can all agree that an online shopping experience today can pretty much emulate an in-store shopping experience with regards to having a salesperson making recommendations and directing us to new products that are in fact, right up our alley of preference. Admittedly, more than once I have found it a little creepy how much I end up liking some of the recommendations made to me whether it’s on Amazon and clothing sites, or even on streaming sites like Netflix, etc. I guess this means that they are doing it right!
One of the conclusions from the ‘Netflix Prize’ — which was an open competition held by Netflix to discover the best algorithm to predict users’ ratings for films — was that it is extremely simple to produce reasonable recommendations, but extremely difficult to improve them.
So, if you are someone looking to build an application that will make recommendations that are bang on, what will that take?
This article will explore the traditional, but successful, approaches to recommender systems- collaborative filtering and content-based recommendation. It will also highlight some of the shortcomings of each approach and how to overcome them.
Introduction
What is the “recommendation problem”?
The problem is to find a utility function that estimates how a user will like an item based on the user’s past behavior, his similarity to other users, the similarity of the item to other items, content description, and so on.
A brief summary of Recommendations Approaches:
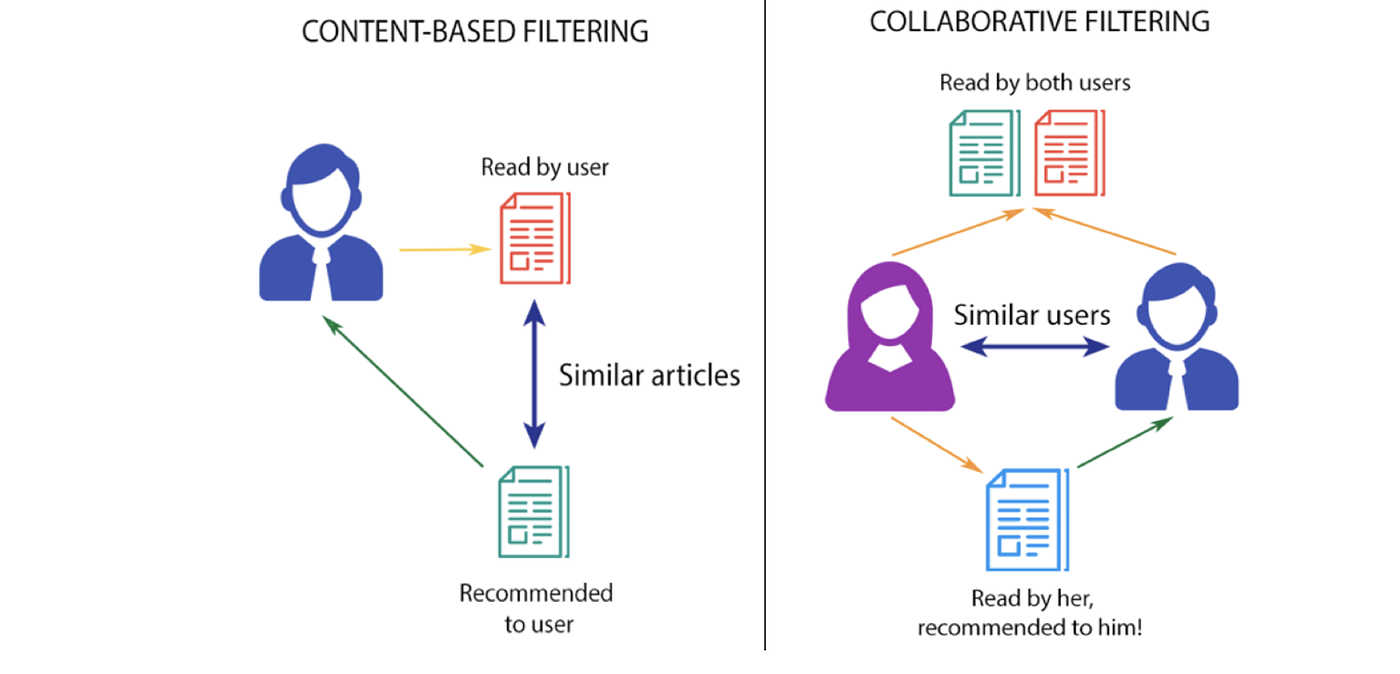
- Collaborative Filtering: Used to recommend items purely based on the users’ past behaviour.
Its an agnostic algorithm which means — it doesn’t matter whether the algorithm is trying to recommend movies, books, products, etc. No knowledge about the domain is required. Two sub-types of this approach are:
— User-based approach: To find users similar to the target user and recommend what they liked
— Item-based approach: To find similar items to those the user has previously liked - Content-based Approach: Pretty much the opposite of collaborative filtering; users’ past behaviour is not really given much importance. It recommends new items based on item features or descriptions.
- Personalised Learning to Rank: This treats recommendation as a ranking problem (both collaborative filtering and content-based)
- Demographic Approach: It recommends new items based on user features
- Social Recommendations: Trust-based ( leveraging existing relationships between users)
- Hybrid Approach: Combine any of the above methods
Recommendation as Data Mining:
Recommendation can be assimilated to a general data mining problem as depicted below:

Serendipity:
Most recommender systems suggest items that are popular among all users and similar to items a user usually consumes. As a result, the user receives recommendations that she/he is already familiar with or would find anyway, leading to low satisfaction. To overcome this problem, a recommender system should:
- Enable unsought finding — something a user didn’t know he/she was looking for
- Suggest novel, relevant and unexpected i.e., serendipitous items
- Expand the user’s taste into neighbouring areas
Collaborative Filtering can offer controllable serendipity — it knows how many neighbours to use in the recommendations.
What works and what matters:
Before anyone starts on building a recommender system, they would want to start with something that they know works. Although it largely depends on the domain and what the particular problem is, it can be safely said that the best isolated approach is Collorative Filtering. Other approaches can be hybridised to improve results and address issues like the cold-start problem.
What matters:
- Data preprocessing: Outlier removal, denoising, removal of global effects (eg: individual user’s average)
- Smart dimensionality reduction using Matrix Factorization, SVD
- Combining methods
Collaborative Filtering (CF)
As previously introduced, collaborative filtering is an approach that is completely agnostic to the items it is recommending. It works purely on users’ past behaviours.
The CF Ingredients:
- List of ‘m’ users and list of ‘n’ items
- Each user has a list of items with an associated opinion. An opinion could be:
- Explicit like a rating score
- Implicit like purchase records, etc.
It is important to note that explicit ratings can be noisy and biased — eg: Consider a documentary that won an Oscar, a user might give it an aspirational rating of 5 stars. This doesn’t necessarily mean that the user wants to be recommended more and more documentaries.
Moreover, explicit data is much harder to get. If you are aiming for big data, implicit is the way to go, since it is much more readily available and the user does not have to take any extra steps. - Active user for whom the CF prediction task is being performed
- Metric for measuring similarity between users
- Method for selecting a subset of neighbours
- Method for predicting a rating for items not currently rated by the active user
Basic steps of Collaborative Filtering:
- Identify set of ratings for the target/ active user
- Identify set of users most similar to the target/ active user according to a similarity function (neighbourhood formation)
- Identify the products these similar users liked
- Generate a prediction of the rating that would be given by the target user to the product — for each one of these products
- Based on this predicted rating, recommend a set of top N products
Advantages of Collaborative Filtering:
- Requires no domain knowledge
- Helps users discover new interests — serendipity
- Extremely simple approach and produces good enough results in most cases
Disadvantages of Collaborative Filtering:
- Requires a large number of reliable user feedback data points to bootstrap
- Requires products to be standardised (users should have bought exactly the same product — which is very difficult for large catalogue of items like in the case of Amazon)
- Assumes that prior behaviour determines current behaviour without taking into account “contextual” knowledge. For example, a user making a one-time purchase of furniture when moving house does not want to be recommended more furniture following that.
There are some limitations or shortcomings to this approach that are addressed below like the ‘cold-start’ problem.
Personalised vs Non-personalised CF:
- CF recommendations are personalised since the “prediction” is based on ratings expressed by similar users. Those neighbours are different for each target user.
- A non-personalised collaborative-based recommendation can be generated by averaging the recommendations of ALL the users.
A baseline or first approach to try out would be to suggest the most popular choice. If your CF based recommendation doesn’t do better than the most popular, you’re doing something wrong.
User-based CF:
We find the closest neighbours to a target user and then compute predictions for the target user based on weighted computation of its neighbours.
Similarity between target user and his neighbours can be computed by Pearson correlation. Weights can also be assigned to users in the neighbourhood based on their varying similarities.
However, the downside of restricting the number of users — using a subset of neighbours is that sometimes those neighbours may not have rated a product. It leads to data sparsity. It will happen very often if dimensionality of space is large. It will force us to use a large neighbourhood, which in turn, is computationally inefficient.
Challenges of Nearest Neighbour CF:
- Sparsity
- Accuracy of recommendation may be poor
- Scalability
- Poor relationship among like minded but sparse-rating users
The sparsity problem:
- Typically, for large product sets, there are user ratings for only a small percentage of it.
For example — Amazon has millions of books. The probability that two users that have bought 100 books each have a common book in a catalogue of 1 million books is 0.01 - Standard CF must have a number of users comparable to one-tenth of the size of the product catalogue
The scalability problem:
- Nearest neighbour algorithms require computations that grow with both the number of customers and the number of items
- Worst case complexity is ‘mn’ (where ‘m’ is number of customers, ‘n’ is number of products)
The solution — Matrix Factorization:
The solution is the usage of latent models to capture similarity between users and items in a reduced dimensional space.
The basic idea of matrix factorization (MF) is- instead of a matrix representing items which is going to be a sparse space, we use topics to compact space into something much smaller.
Item-based CF:
In the approach, we still do not know anything about the items. We will be basing it on users’ actions. This means that if the same users likes two different types of items, we consider those items to be similar.
Algorithm:
- Look into the items the target user has rated
- Compute how similar they are to the target item
- Similarity is calculated only using past ratings from other users
- Select ‘k’ most similar items
- Compute prediction by taking weighted average on the target users’ ratings on the most similar items
Item Similarity Computation:
The similarity can be — cosine similarity, correlation-based similarity, adjusted cosine similarity
Limitations to Collaborative Filtering::
- Cold start problem: The system cannot draw any inferences for users or items about which it has not yet gathered sufficient information.
- Popularity bias: It is hard to recommend items to someone with unique tastes, because CF tends to recommend popular items (items from the tail end do not get so much data)
Cold start problem:
- New user problem: To make accurate recommendations, the system must first learn the user’s preferences from the ratings. However, several techniques exist to address this problem. Most use hybrid approach, which combines content-based approach with CF to address this problem.
- New item problem: New items are added regularly to recommender systems. Until the new item is rated by a substantial number of users, the system is not able to recommend it. The solution to this is to have content based strategy or have an “Explore New Items” strategy.
Content-based Approach
- A pure content based system makes recommendations for a user based solely on the profile built up by analysing the content of items which the user has rated in the past
- Recommendations based on information about the content of items rather than on users’ opinions and interactions
- Uses a machine learning algorithm to induce a model of the users’ preferences from examples based on a feature description of the content
What is content?
- It can be explicit attributes or characteristics like genre, year, actors, etc
- It can also be textual content (tittle, description, table of content, etc) using NLP
- It can also analyse signals of audio and video
Advantages of Content-based Approach:
- No need for data on other users
- No cold start or sparsity problems
- Able to recommend to users with unique tastes
- Able to recommend new and unpopular items
- Can provide explanations of recommended items by listing content features that caused the item to be recommended
Disadvantages of Content-based Approach:
- Requires content that can be encoded as meaningful features
- Some kind of items are not amenable to easy feature extraction methods (eg: movies, music)
- Even for texts, Information Retrieval techniques cannot consider multimedia information
- Users tastes must be represented as a learnable function of these content features
- Hard to exploit quality judgements of other users
- Difficult to implement serendipity
- Easy to overfit (pigeon hole)
- This approach will perform only as good as the descriptions
Conclusion
The era of search has come to an end.. long live the era of recommendation! This article was a short dive into the world of recommender systems. It explored the more traditional methods of building a recommendation system. Although simple, collaborative filtering has proven over and over to provide pretty good results. In combining it with other methods like content-based approach, you will end up with an excellent system capable of knowing your users better than they know themselves!